VGGT-Long
VGGT-Long: Chunk it, Loop it, Align it – Pushing VGGT’s Limits on Kilometer-scale Long RGB Sequences
VGGT-Long 的核心并不是重新训练一个新的 3D 基础模型,而是把 VGGT 作为强局部几何估计器,并在其外部构造一个适用于长序列的轻量级全局框架。论文中,这一框架可以概括为三个动作:Chunk it、Loop it、Align it;官方仓库则进一步把它落实为“分块推理、重叠对齐、回环约束与 chunk 级 LM 优化”的工程流程。
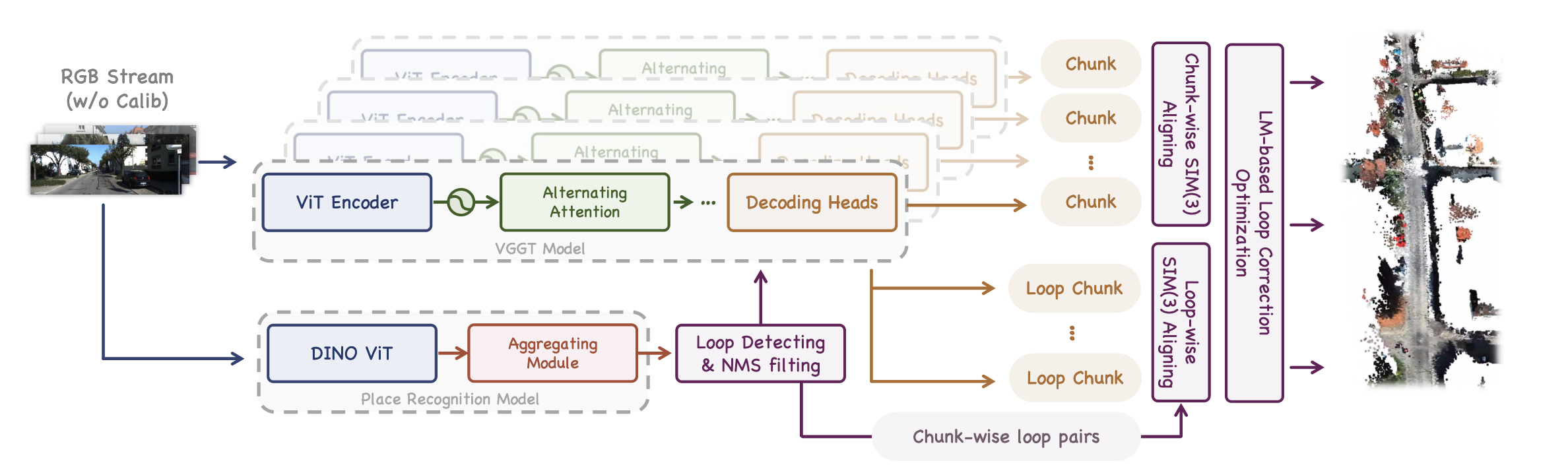
整体框架
给定图像序列 $\mathbb{I}={I_1,\dots,I_n}$,VGGT-Long 首先将其切分为 $K$ 个带重叠的子序列,然后分别调用 VGGT 进行局部重建。接着,它利用相邻 chunk 的重叠帧估计局部 $\mathrm{Sim}(3)$ 变换,再通过回环检测补充远距离约束,最后在 chunk 层面对整条序列执行一次全局 $\mathrm{Sim}(3)$ 优化。
1 | # 简化后的 VGGT-Long 主流程 |
这一设计的关键在于:VGGT 只负责局部准确性,而长程一致性由 chunk 级的几何对齐与优化来保证。因此,系统的可扩展性主要来自外层框架,而不是来自对 VGGT 本体的改造。
1. Chunk it: 分块推理与局部重建
设每个 chunk 的长度为 $L$,相邻 chunk 的重叠长度为 $O$,则步长为 $L-O$。第 $k$ 个 chunk 可写为
对每个 $C_k$,VGGT 输出局部一致的一组相机外参、内参、深度、世界坐标点图以及逐点置信度。论文中实验设置为:KITTI / Virtual KITTI 使用 chunk_size=75、overlap=30,Waymo 使用 chunk_size=60、overlap=30;官方仓库的 kitti.yaml 与 waymo.yaml 也与这一设置一致。
1 | step = L - O |
VGGT 输出的置信度反映了模型对这个像素预测点云的不确定性,通常置信度越高,这个点估计的越准确;而动态物体、天空(深度无限远)、雨滴等物体的置信度较低。
仓库实现中还有一个很重要但论文里只简要提到的工程点:每个 chunk 的预测结果会先保存到磁盘,而不是一直保留在内存中。这样做虽然牺牲了一些 I/O 时间,但能显著缓解长序列场景下的 CPU 内存压力。
2. Align it (局部): 相邻 chunk 的重叠对齐
对于每个相邻块 $C_k$ 和 $C_{k+1}$,系统只使用它们的重叠帧建立 3D 对应。设重叠区域中的点对为 ${(p_k^i,p_{k+1}^i)}$,则需要估计一个从 $C_{k+1}$ 到 $C_k$ 的相似变换 $S_{k,k+1}\in \mathrm{Sim}(3)$。其目标是最小化
其中 $\rho(\cdot)$ 为 Huber 损失。该鲁棒优化通过 IRLS 近似为一系列加权最小二乘问题:
其中
这里的 $\tilde c_i$ 是置信度权重。论文只强调“利用置信度抑制不可靠点”;而官方仓库的实现更具体,采用
并在对齐前先过滤掉低于阈值的点。仓库中该阈值实现为
因此,动态物体、天空和其他低置信区域会被弱化甚至直接剔除。
1 | # 相邻 chunk 的重叠对齐 |
从算法本质上看,这一步的作用是把 VGGT 输出的局部坐标系串联起来,形成一条“顺序约束链”。论文中的“Chunk it”强调的是可扩展性,而这里的“Align it”则负责把这些局部块真正拼成一条长轨迹。
3. Loop it: 回环检测与 loop-wise 对齐
仅依赖顺序对齐会产生累计漂移,因此 VGGT-Long 还会在整条序列上执行回环检测。论文中这里使用基于 DINOv2 的 VPR 模型;官方仓库默认使用 SALAD + DINOv2 + FAISS,并保留了 DBoW2 作为可选的 CPU 路径。
回环候选图像对 $(i,j)$ 需要满足两个条件:
- 相似度高于阈值;
- 时间间隔足够大,以避免把近邻帧误当成回环。
随后,系统对候选结果执行 NMS,以抑制时间上彼此接近的冗余匹配。仓库默认参数为:top_k=5、similarity_threshold=0.85、nms_threshold=25,并要求 |i-j| > 10。
1 | # 回环候选筛选 |
对于每一个保留下来的回环对 $(i,j)$,系统不会直接在两张图之间求变换,而是分别截取以 $i$、$j$ 为中心的局部子序列,将它们拼接成一个新的 loop chunk,再次送入 VGGT 估计。设该 loop chunk 与原始 chunk $C_a$、$C_b$ 的对齐结果分别为 $S_{a,\mathrm{loop}}$ 与 $S_{b,\mathrm{loop}}$,则可间接得到两块之间的回环约束:
这一步的关键不是“闭环检测”本身,而是通过一个共享的、高质量的 loop-centric reconstruction,把两个时间上相距较远的 chunk 连接起来。
1 | # loop-wise Sim(3) 构造 |
这里还有一个容易忽略的实现细节。由于 chunk 存在重叠,同一帧可能同时属于两个 chunk。仓库中 find_chunk_index() 通过对 chunk 起始位置做 bisect_right 查找,因此若一帧同时落在两个 chunk 中,会优先分配给后一个 chunk,而不是做额外的最优匹配。
4. Align it (全局): chunk 级 $\mathrm{Sim}(3)$ LM 优化
有了顺序约束和回环约束之后,VGGT-Long 在 chunk 层面对所有块的全局位姿进行统一优化。设每个 chunk 的全局变换为 $S_k \in \mathrm{Sim}(3)$,则论文将优化问题写为
其中 $\log_{\mathrm{Sim}(3)}$ 将李群上的误差映射到 7 维李代数,从而可以在线性空间里求解。与传统大规模 BA 或完整因子图不同,这里优化变量不是所有帧,而只是所有 chunk 的 $\mathrm{Sim}(3)$ 变换,因此变量规模很小,优化也更轻。
官方仓库中这一部分使用 PyPose 表示 $\mathrm{Sim}(3)$,并实现了一个典型的 Levenberg-Marquardt 迭代:若本次更新使代价下降,则接受更新并减小阻尼;否则拒绝更新并增大阻尼。
1 | # 全局 LM 优化 |
从框架设计上说,这一步才真正把前面的“局部拼接”变成“全局一致”。因此,VGGT-Long 的整体逻辑可以理解为:先用 VGGT 解决局部几何,再用 $\mathrm{Sim}(3)$ 图优化解决全局漂移。
总结
VGGT-Long 的方法并不复杂,但非常有效。它的关键不在于设计了一个更重的系统,而在于把 VGGT 的输出组织成了一个适合长序列的几何优化问题:
- 用 chunk 解决显存与计算瓶颈;
- 用重叠帧对齐相邻 chunk;
- 用回环约束抑制累计漂移;
- 用 chunk 级 LM 获得全局一致的结果。
这也是它相较于许多 foundation-model 直接长序列推理方案更可行的原因。
引用与补充说明
论文与代码
IRLS
目标函数
其中 $r_i(\theta)$ 是第 $i$ 个点的误差,$\rho(\cdot)$ 是鲁棒损失。第 $t$ 轮先用当前参数算残差 $r_i^{(t)}$,再更新权重
然后解一个新的加权最小二乘问题
Umeyama
给定对应点 $(x_i,y_i)$ 与权重 $w_i$,先计算两组点的加权中心
然后把每个点减去各自中心,比较两组点云的相对形状。为此构造协方差矩阵
其中 $\bar w_i = \frac{w_i}{\sum_j w_j}$ 是归一化权重。接着对 $\Sigma$ 做 SVD,由此得到旋转
通过对 $s$ 求导令 $0$ 计算尺度,最后补上平移
LM
设当前优化变量为 $\xi$,残差向量为 $r(\xi)$。在当前点附近,把残差线性化为
这里的 $J$ 是雅可比矩阵,可以理解为“参数轻微变化时,误差会怎样变化”;$\Delta \xi$ 是这一轮准备更新的量。
然后解阻尼正规方程
阻尼系数 $\lambda$,控制更新:
$\lambda$ 小时,更像高斯牛顿,走得更快;
$\lambda$ 大时,更像梯度下降,走得更稳。
如果更新后总代价下降,就接受这一步,并减小 $\lambda$;如果更新后总代价没有下降,就拒绝这一步,并增大 $\lambda$。