研究总结
梳理
多模态融合
不同模态具有互补信息
- 特征级融合
- 查询级融合
- 实例级融合
特征级融合
- 晚期融合
- 中期融合
- 早期融合
晚期融合:
晚期融合一般是在proposal上进行融合,如MV3D、Frustum PointNet等:
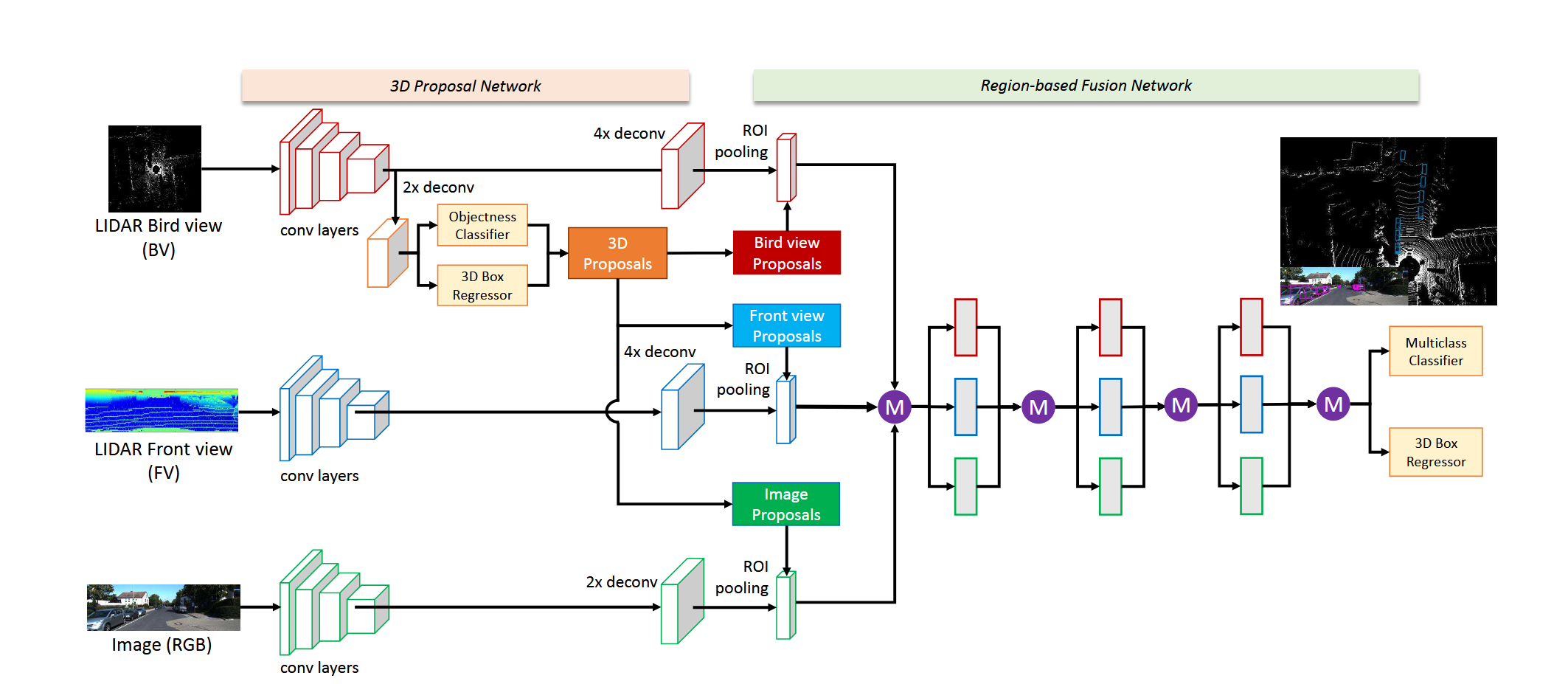
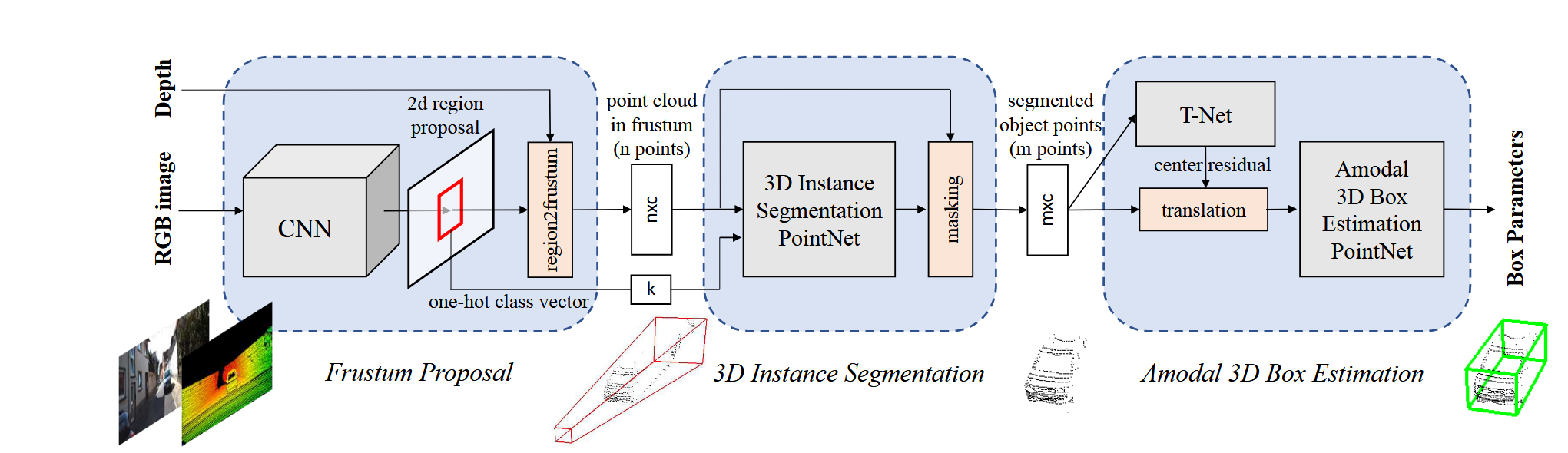
MV3D利用点云生成的proposal来指导融合,而Frustum PointNet利用图像生成的proposal通过深度采样和投影变换实现多模态的融合,这类方法倾向于单一模态,未能充分利用模态间的互补信息,在单一模态失效的情况下严重影响模型性能
早期融合
早期融合一般是在输入层级上进行融合,如PointPainting和PointArgumenting:
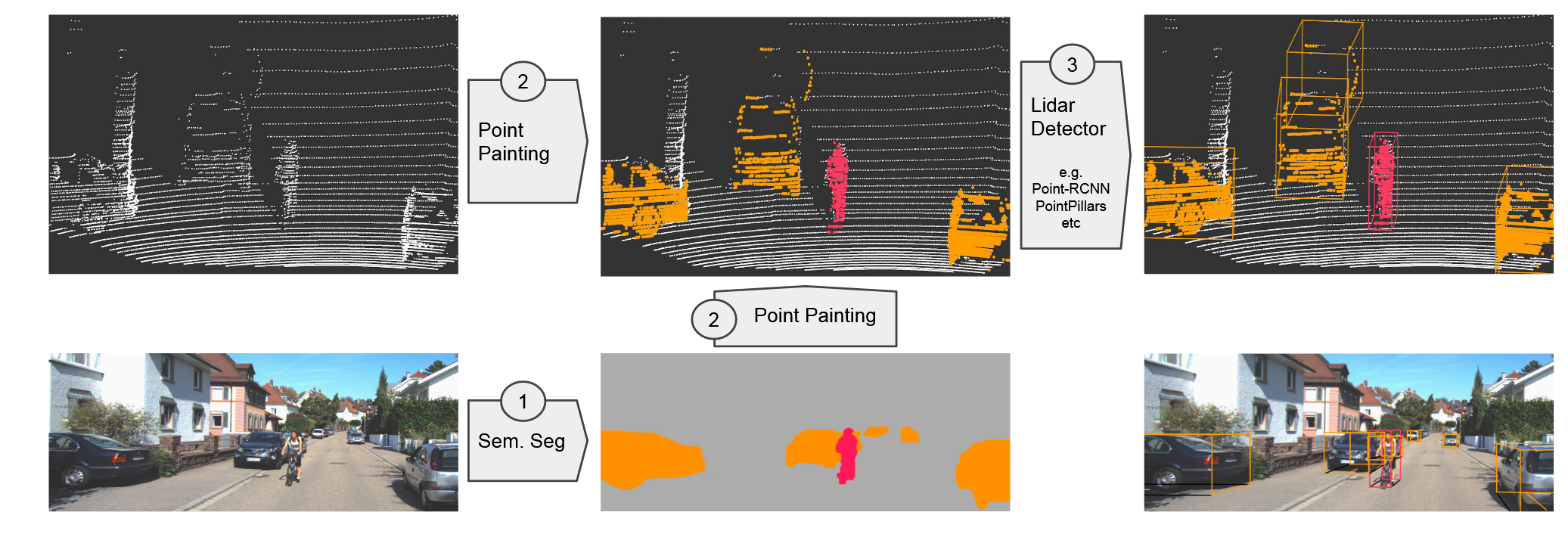
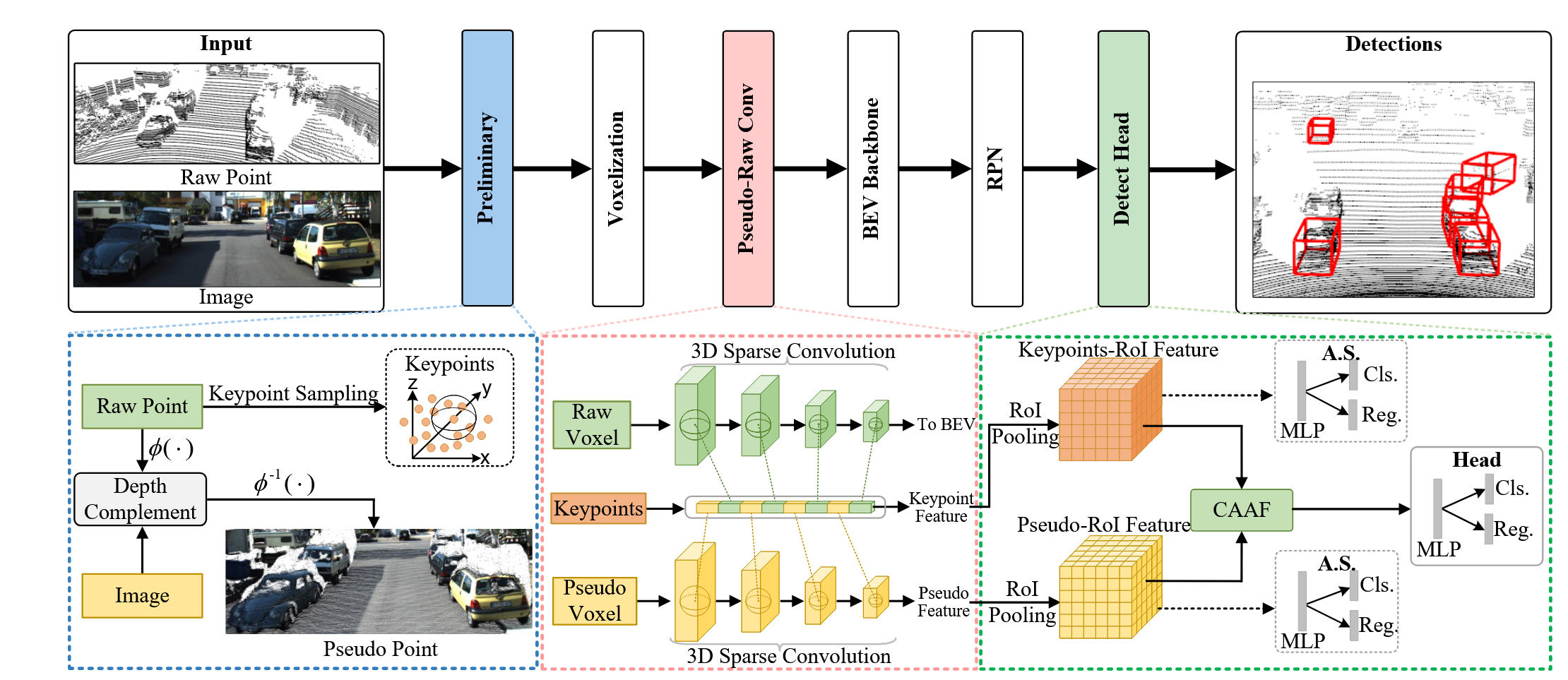
PointPainting将图像的语义分割分数经深度估计和投影变换paint在对应的点云上,将图像语义信息融合;PointArgumenting进一步利用图像生成伪点云,并入原始点云,这类方法仍然依赖于单一模态,并且图像的语义信息在投影过程中会有很大损失;而FGU3R通过深度补全网络将图像转换到点云模态
上述方法都存在从一个模态投影到另一个模态的过程,这个操作不可避免地会带来一些信息损失:

- 点云投影到相机会损失几何信息,例如深度有关的信息
- 图像投影到点云由于数据结构的不一种,密集图像的大量像素点没有相应的点云匹配
中期融合
中期融合是目前的主流融合方法,通过将两个模态映射到统一空间,并进行特征层级的融合
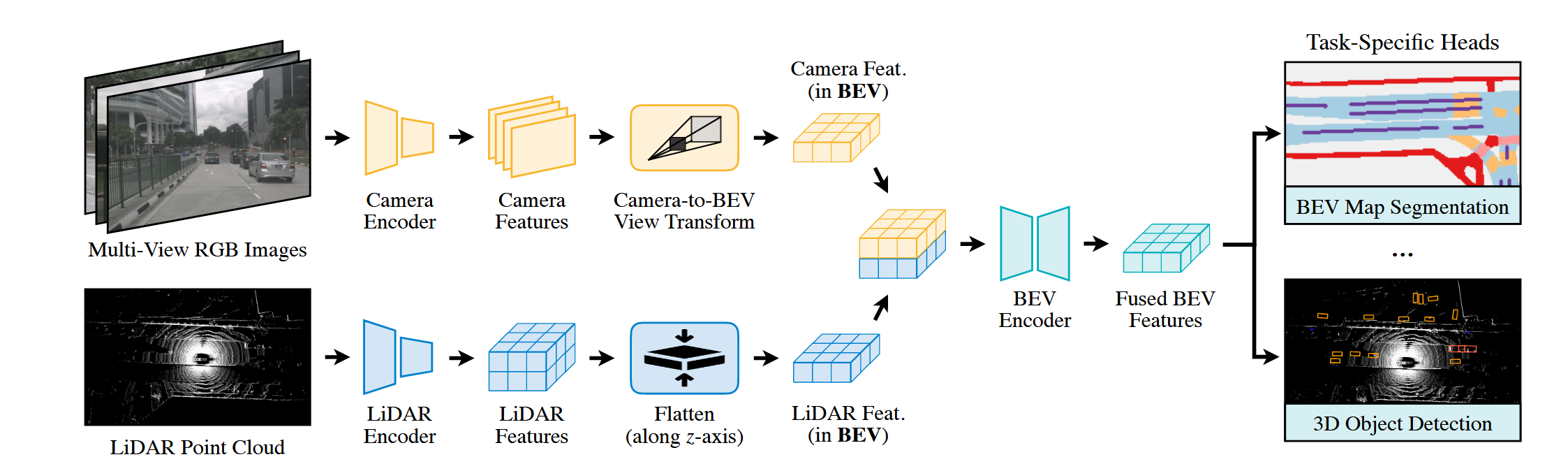
BEVFusion通过在模态特定的分支上各自提取特征并将图像和点云都变换到鸟瞰视图进行特征融合,充分保留了几何结构和语义信息
查询级融合
受益于transformer系列研究,以query的形式融合模态特征
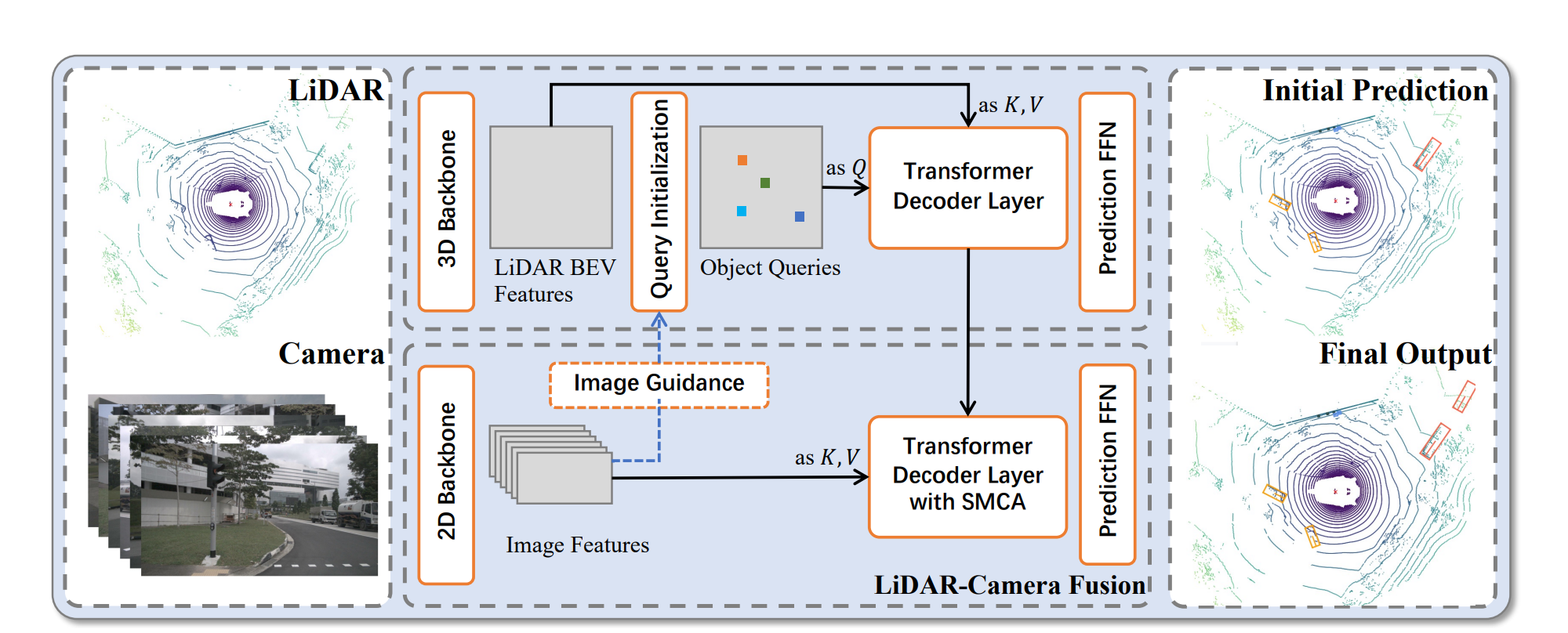
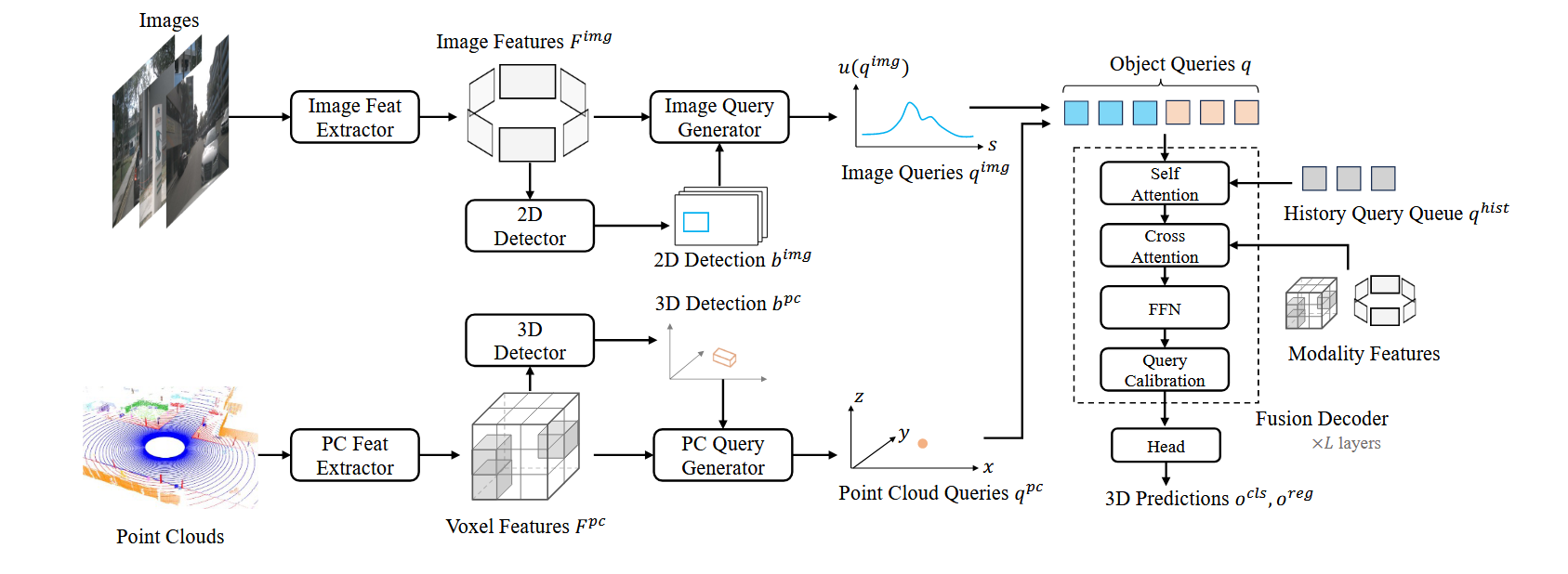
MV2DFusion通过模态特定的检测分支生成模态特定的查询,最后在query层级通过解码器进行特征融合
实例级融合
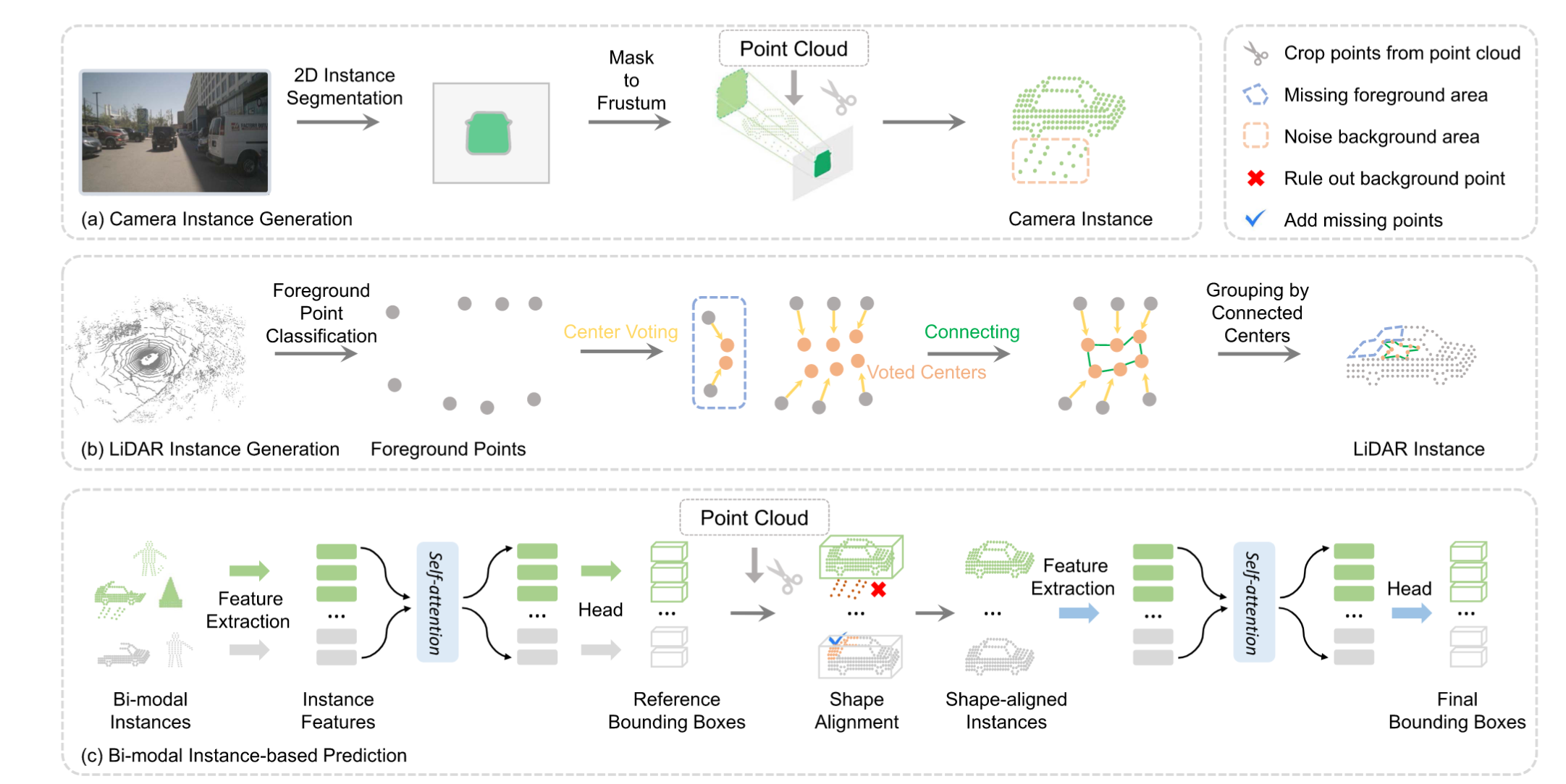
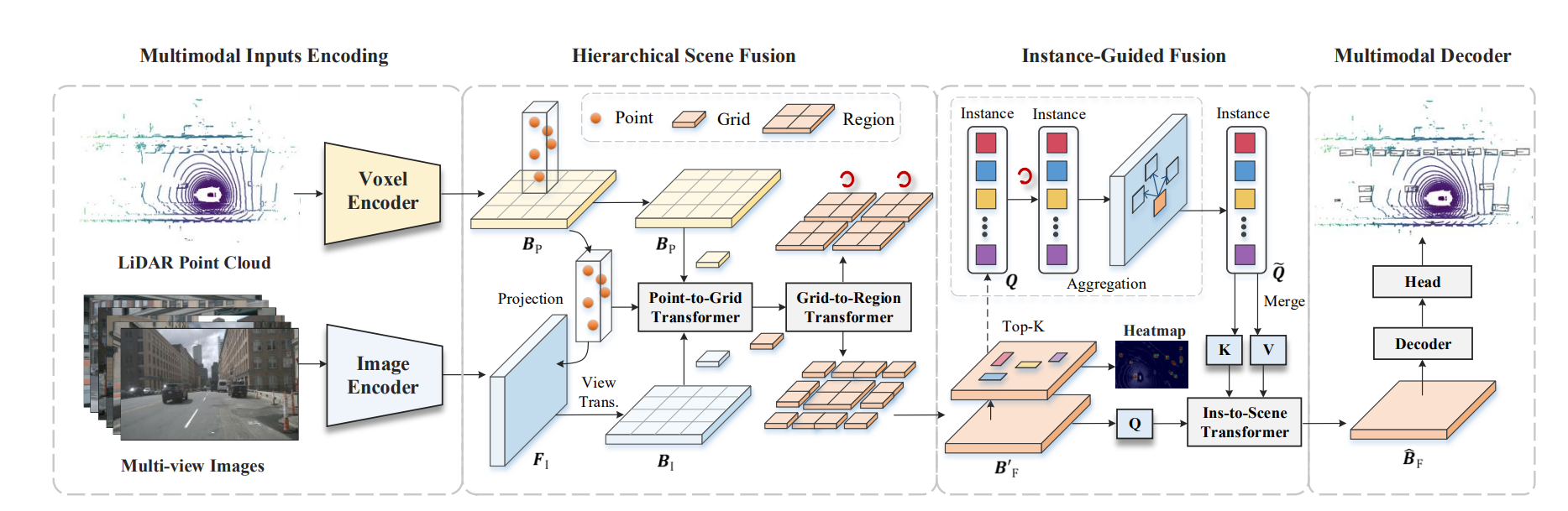
Fully Sparse Fusion通过分割网络对各自模态实现实例级分割,最后再分割是实例上进行基于Transformer架构的融合;而Is-Fusion实现了场景级与实例级的融合,先在全局特征上进行场景级融合,然后生成相应实例并在实力层级进一步进行融合
存在的问题
对抗模态失效/鲁棒性问题
对抗模态失效指的是单一模态失效、模态噪声抑制的情况下,模型性能显著退化,尤其是对于一些依赖于单一模态的架构,如MV3D、Frustum PointNet等。
一些研究旨在BEV特征融合时进行自适应融合,使得模型自动选取有利特征:
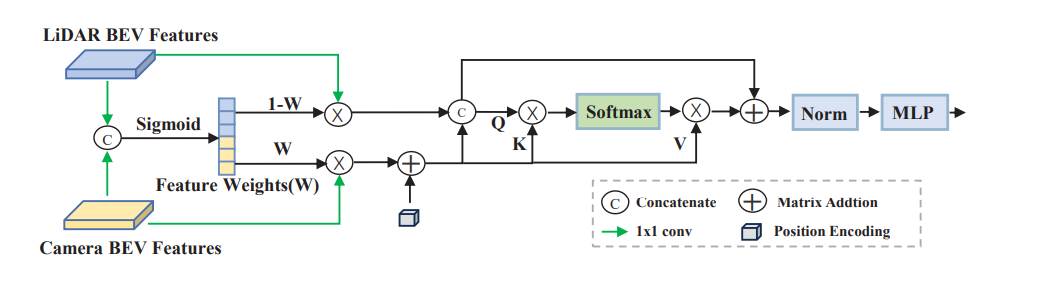
GaFusion在BEV特征融合时通过雷达引导,实现自适应特征融合;进一步,ReliFusion通过对每个模态生成置信度分数,加权融合最终特征。
此外,一些研究引入时空建模解决模态鲁棒性问题:
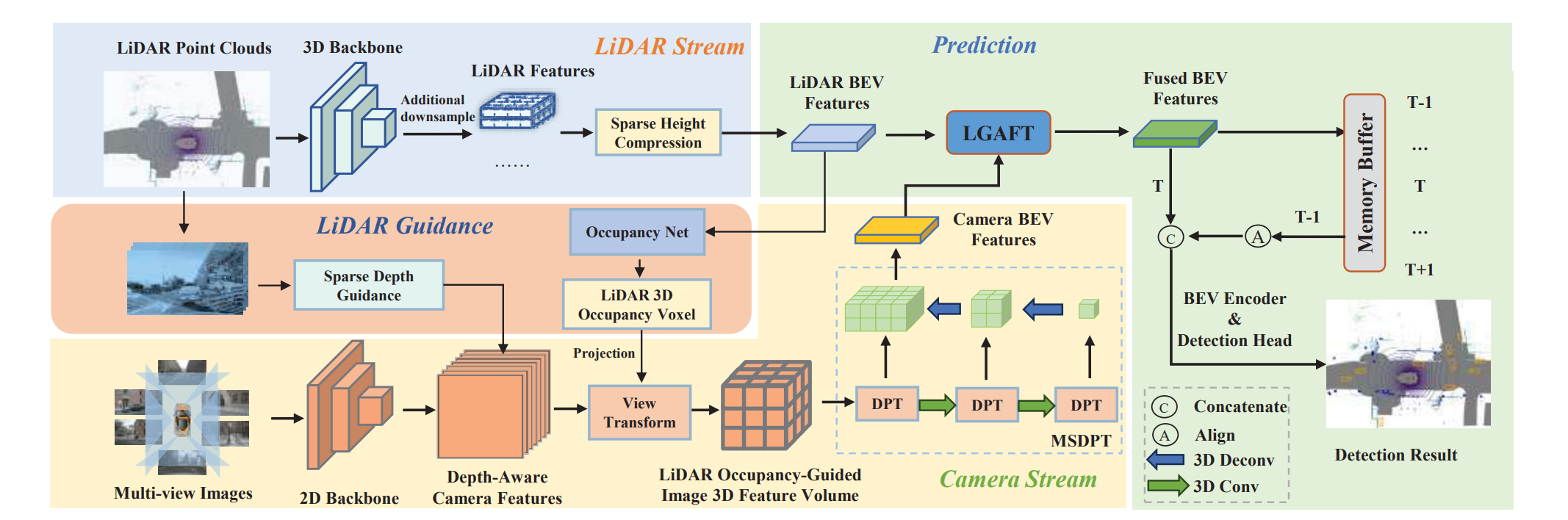
GAFusion通过类似于BEV4D的记忆单元,引入时空特征。
跨模态对齐
模态对齐一般指的是几何上的对齐与语义上的对齐,跨模态对齐对于模型性能的相关性显著。
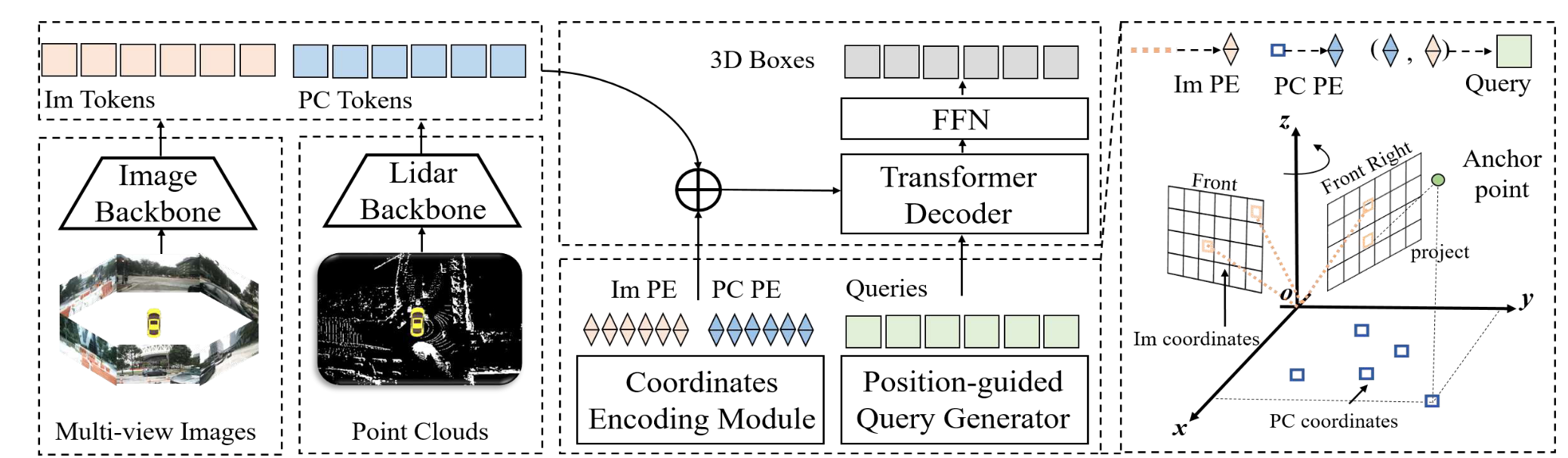
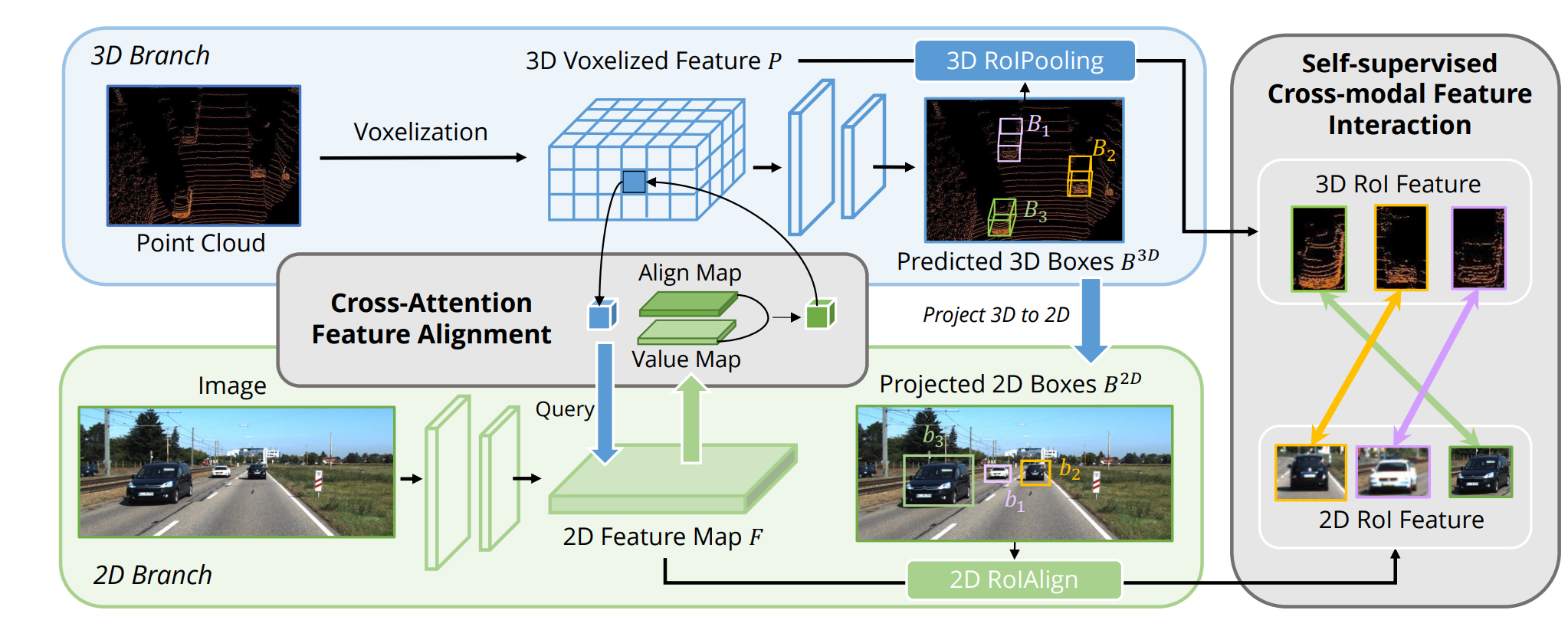
CMT通过将二维、三维的坐标编码引入解码器,实现跨模态的对齐;AutoAlign利用可变形卷积学习从图像特征中采样与点云位置对应的局部区域,从而聚合时自动校准偏差。
模态信息交互不足
仅在决策级融合的网络未能让模型在前期就学习到模态间的互补信息,而特征级融合的网络如BEVFusion在生成图像BEV时也忽略了雷达精准几何信息的价值,例如,GAFusion在图像BEV生成的过程中,直接利用点云深度信息。
一些想法
不同模态的噪声/不确定性是否可以定量衡量?如何利用定量衡量的噪声平衡不同模态特征的贡献,使模型能在模态失效的情况下仍然能实现较好的性能?
时空依赖建模仅在最终融合特征/proposal/query交互是否能有效利用不同时间步和不同模态间的信息?是否可以设置局部到全局的时空依赖建模?
模态对齐过程中,如何实现更好的几何对齐和语义对齐?标定参数是否能够校准?对比学习如何在特定的点云和图像两模态下拉进语义一致性?
如何充分利用模态信息?如何协同多层级的融合机制?点云的深度信息如何辅助图像BEV生成?模态失效的情况下如何惩罚?模态“三原色”理论:冗余信息、模态特定信息、模态协同下的新信息
分离时空张量补全能否扩展到多模态融合以应对对抗模态缺失?

