多模态目标检测
多模态目标检测
MV3D: Multi-View 3D Object Detection Network for Autonomous Driving
概述
MV3D是多模态特征级融合方法,核心思想是建立一个端到端的双阶段的检测网络,核心架构如图所示:
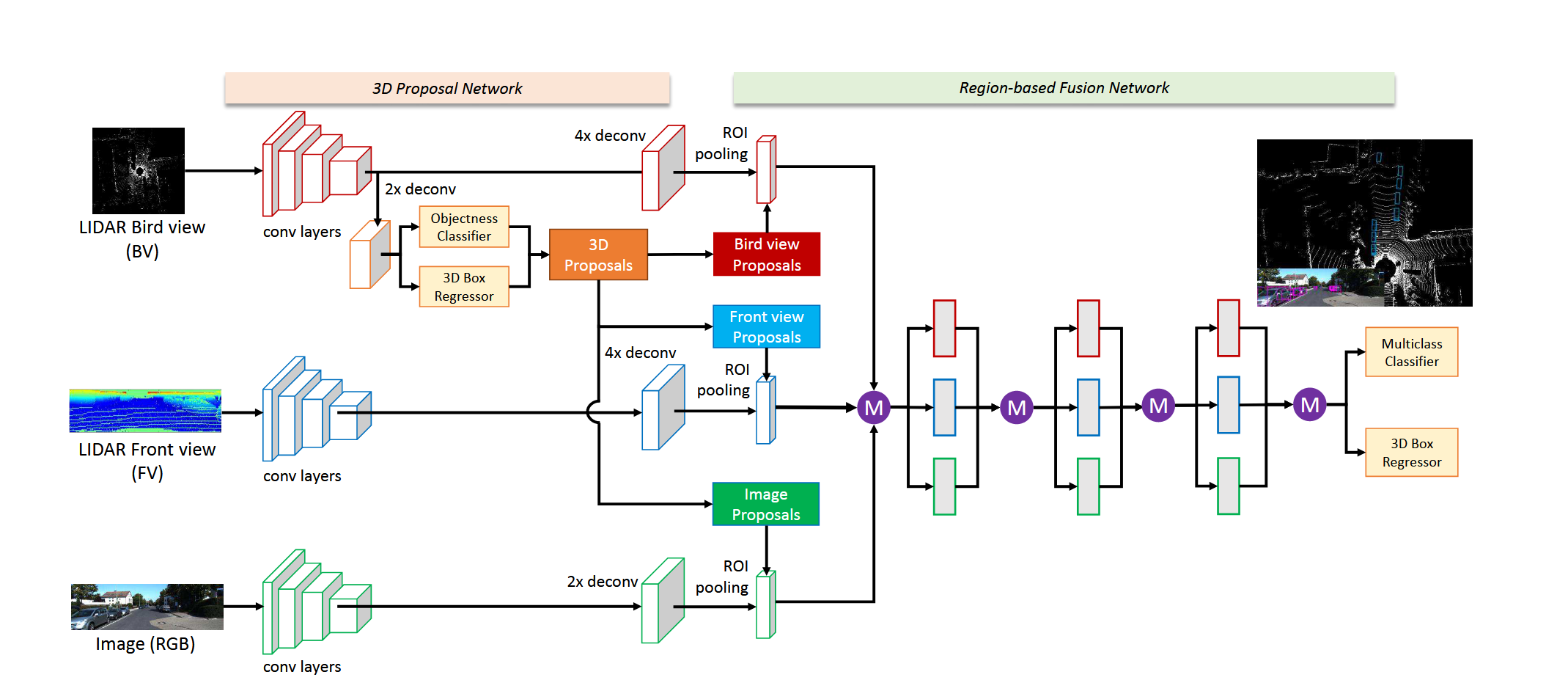
首先对三维点云进行预处理投影到二维BV视图和FV视图,分别针对高度、密度、反射强度进行计算。在BV视图中,对高度进行切片,并取cell内的最大值作为相应像素值,因此BV的通道数为M+2;

双阶段网络分别:RPN+基于ROIs的Deep Fusion。通过VGG网络提取各模态特征,并仅通过BV视图生成三维提议,三维提议投影到BV、FV、Image平面分别生成对应提议,根据提议从各模态的特征图中截取出ROIs并通过ROI池化进行对齐,通过堆叠的均值融合模块以及分类和回归分支得到最终的预测结果。网络中的上采样操作旨在解决目标尺度过小的问题。在训练过程中,采取drop-path策略和辅助分支损失策略旨在提高模型鲁棒性,使得每种模态分支都能学到鲁棒的表示,避免在某种模态缺失的情况下,模型性能严重下降。
不足
- 连续点云离散到网格平面导致细粒度空间信息丢失
- 倾向于点云模态,仅使用BEV进行proposal生成,未能充分利用不同模态的互补信息,尤其是图像模态的丰富语义信息
- 均值融合的信息交流不足
Frustum PointNets for 3D Object Detection from RGB-D Data
概述
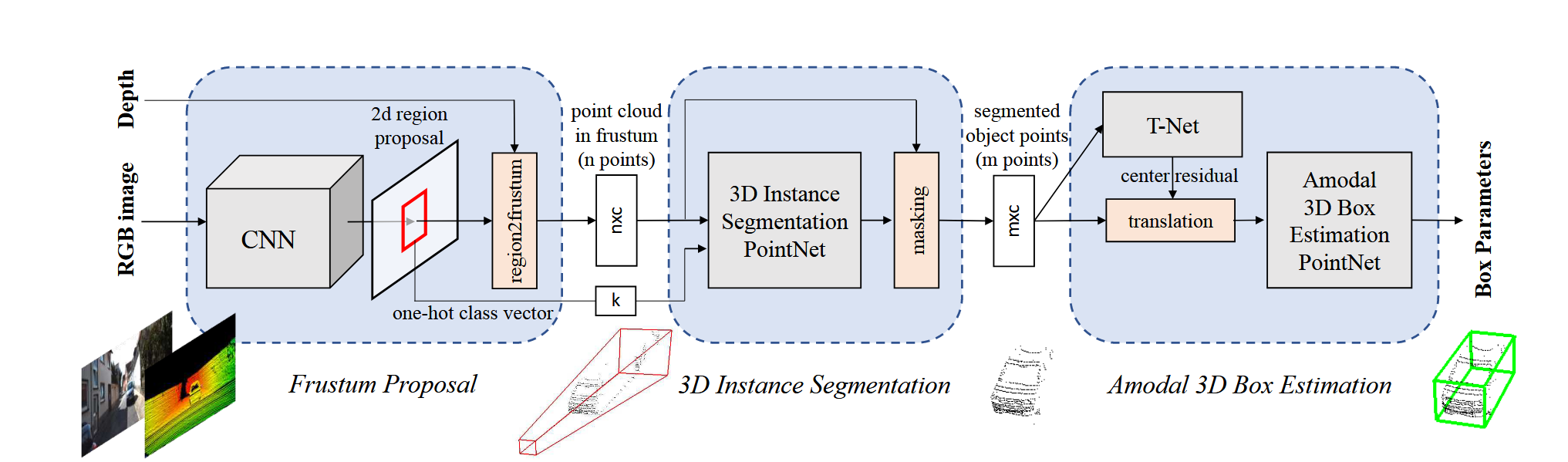
Frustum Pointnet首先利用二维检测器从RGB图像检测出二维边界框,并通过投影变换以及传感器预定义深度值得到三维锥体,对三维锥体执行实例分割,近区分前景和背景;实例分割网络利用二维检测器的one-hot分类向量作为语义补充,学习不同类别目标的特有信息;最后对分割出的实例通过Pointnet进行边界框回归。
不足
- 过度依赖二维检测器,若二维检测器检测失败,则无法构建三维锥体,直接检测失败
- 未能充分点云的三维几何信息、未能充分利用点云和图像的互补信息
- 每个截锥体仅视为一个目标,当目标重叠时无法区分
研究目标:我希望提升检测精度并减少计算开销;
我了解的现有方法:在我的研究中,现有的融合方法分为特征级融合和决策级融合,在特征级融合中又分为前、中、后期融合,但都存在一些信息丢失、信息利用不充分、融合带来的噪声信息干扰、不同模态固有噪声带来的不确定性和不平衡性、不同模态数据结构不一致、难对齐等问题,而在决策级融合方法中,存在模态bias的问题,模型倾向于单一模态的信息;此外,object as query的系列方法,如MV2DFusion虽然通过模态独立的分支解决了bias问题,但是query的生成依赖于模态独立的检测器,可能存在不能充分利用模态互补信息的问题。
新的方法如FGU3R旨在进行模态对齐,通过深度补全网络将图像模态补充深度信息并转化为点云进行统一处理,但是预训练的深度补全网络存在额外开销,整个模型不能实现端到端的训练;
此外,由于点云的长程稀疏性,现有的方法在远距离检测上效果不佳
其他相关领域中,开创性的提出纯基于聚类的DVLO模型用于Odemetry任务,旨在解决融合过程中存在的不对齐问题,但是仅使用多尺度特征的融合以及refinement,对于目标检测的迁移需要相关改进;针对文本和图像的情感任务识别等研究着手于拥抱模态不确定性(EAU)来解决模态固有噪声问题。
数据集:KITTI、nuScene(如需要进行长程任务,则还需要Waymo)
硬件条件:单卡3080
模型架构偏好:倾向于改进现有模型
技术方向:多模态融合、对齐、多尺度融合等


