MV2DFusion
Introduction
不同模态的传感器能够捕获物体的不同属性,有助于从多模态中识别物体:
- 图像含有丰富的纹理信息,但缺乏深度信息(相机到图像的投影属于$ill$-$posed$问题)。
- 点云能够提供精确的三维空间数据,但缺少丰富的语义信息,且由于稀疏性,难以捕捉远距离的物体。
为了利用两种模态的优势,提出多模态融合方法。传统方法主要分为两类:
- 特征级融合:将不同模态映射到统一的特征空间(如$BEV$),或通过统一的注意力机制进行聚合,但难以充分挖掘原始模态中的目标先验信息。
- 提议级融合:先生成各模态的提议,再进行统一融合,但方法往往倾向于单一模态。
针对上述不足,提出了MV2DFusion,其特点为:
- 充分利用模态特定的语义特点;
- 允许集成任意类型的2D、3D检测器;
- 融合策略具有稀疏性,适用于长距离场景;
- 轻松扩展至4D场景。
Related Work
LiDAR-based 3D Detection
- Point-based:直接利用3D点云数据进行检测(如PointCNN、3DSSD、FSD)。
- Voxel-based:将点云转化为稀疏体素进行处理(如SECOND、CenterPoint、Transfusion-L)。
- Pillar-based:将点云投影到2D柱状体平面,使用2D检测方法。
- Range-based:将点云映射到2D平面,进行检测。
Camera-based 3D Detection
使用2D检测器的升级版构建3D检测器:
Motivation
- 多模态信息的互补性 $\Rightarrow$ 模态融合的重要性;
- 特征融合过程中的偏差 $\Rightarrow$ 提议级融合的优化需求;
- 复杂计算开销 $\Rightarrow$ 稀疏策略以降低成本。
Methodology
Overview
模型接受多视图图像和点云作为输入,经过以下步骤得到3D检测结果:
- 各模态通过独立的特征提取器提取特征,并分别生成2D/3D检测结果;
- 查询生成器生成图像查询和点云查询;
- 在融合解码器中更新查询,整合多模态信息形成最终3D预测。
框架示意图如下: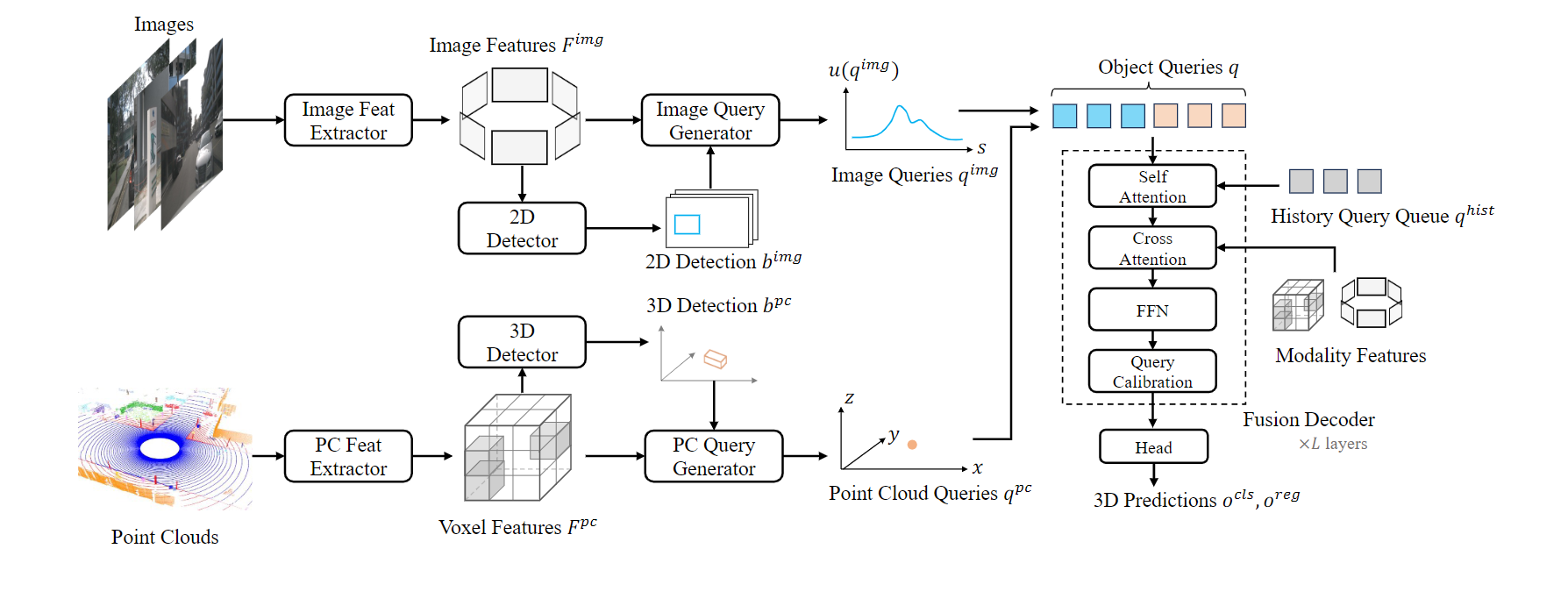
模态特定的目标语义
通过提取模态特定的目标语义进行多模态检测,保留模态独特优势,同时通过稀疏性降低计算和内存需求。特征提取
- 图像模态:利用特征金字塔从多视图图像中提取特征集合,通过$ROI$-$Align$对齐(对齐过程中会丢失相机几何信息)。使用任意检测头得到2D检测集合${b_v^{img}}$。
- 点云模态:采用基于稀疏体素的特征提取网络和检测头,得到3D边界框$b^{pc}$。
查询生成
基于$Transformer$的查询包含两部分:内容和位置。点云查询
目标的世界坐标作为查询的位置部分,内容部分融合外观特征和几何特征:
其中:
图像查询
提出不确定性感知图像查询,其内容部分为$RoI$外观特征并嵌入相机内参的几何特征,位置部分用概率分布表示:
其中:
结合$s^{2d}$和深度估计,通过相机到真实世界的投影,计算出3D采样位置$S^{img}$。
模态信息融合
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Guchen's Blog!
相关推荐



评论